In the previous article, we saw how to launch Spark applications with the Spark Operator. In this article, we’ll see how to do the same thing, but natively with spark-submit. Let’s first explain the differences between the two ways of deploying your driver on the worker nodes.
Client vs Cluster Mode
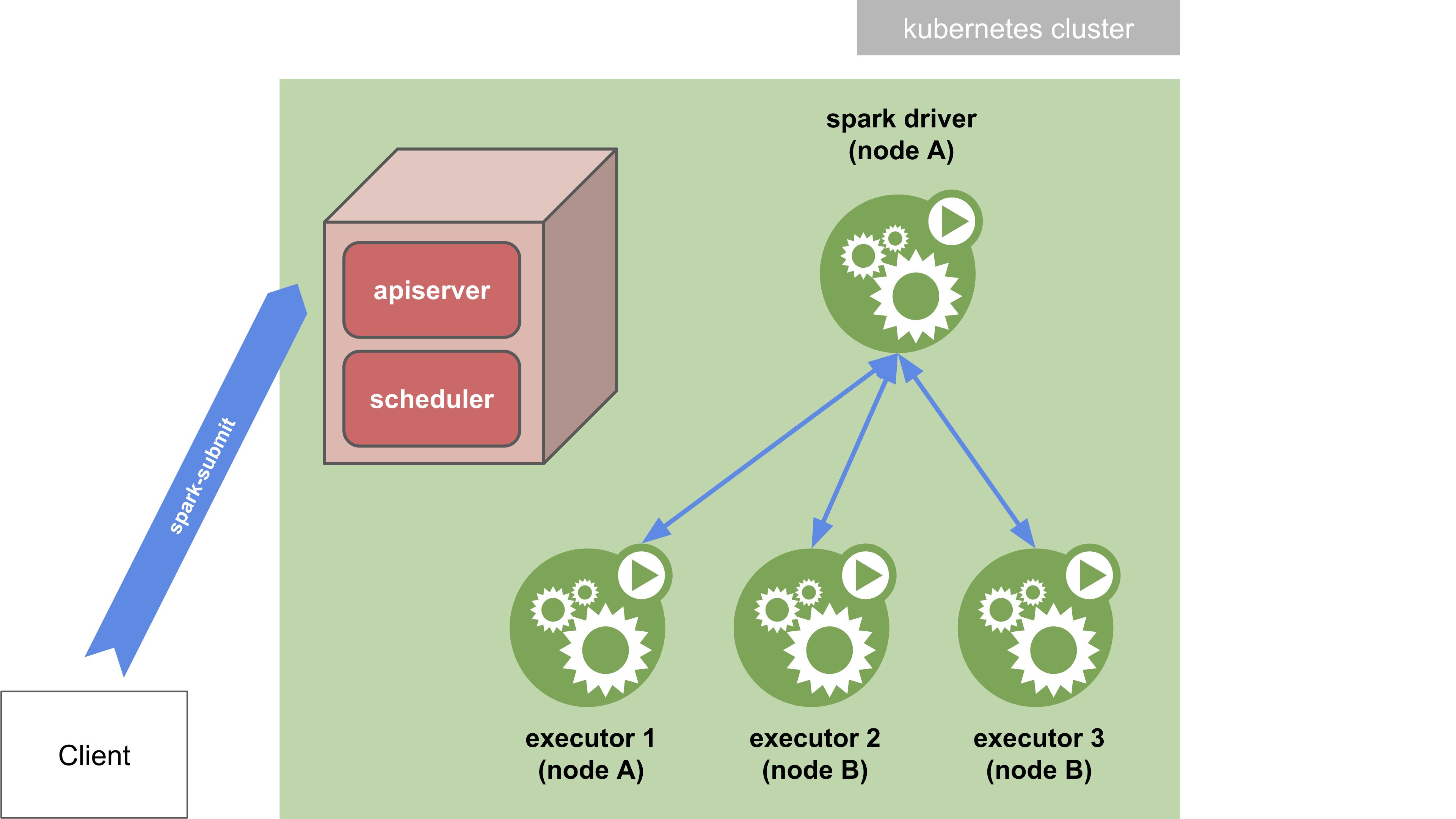
Spark-submit in cluster mode
In cluster mode, your application is submitted from a machine far from the worker machines (e.g. locally on your
laptop). You need a Spark distribution installed on this machine to be able to actually run the spark-submit script.
In this mode, the script exits normally as soon as the application has been submitted. The driver is then detached and
can run on its own in the kubernetes cluster. You can print the logs of the driver pod with the kubectl logs command
to see the output of the application.
It is possible to use the authenticating kubectl proxy to communicate to the Kubernetes API.
The local proxy can be started by:
kubectl proxy &
If the local proxy is running at localhost:8001, the remote Kubernetes cluster can be reached by spark-submit by
specifying --master k8s://http://127.0.0.1:8001 as an argument to spark-submit.
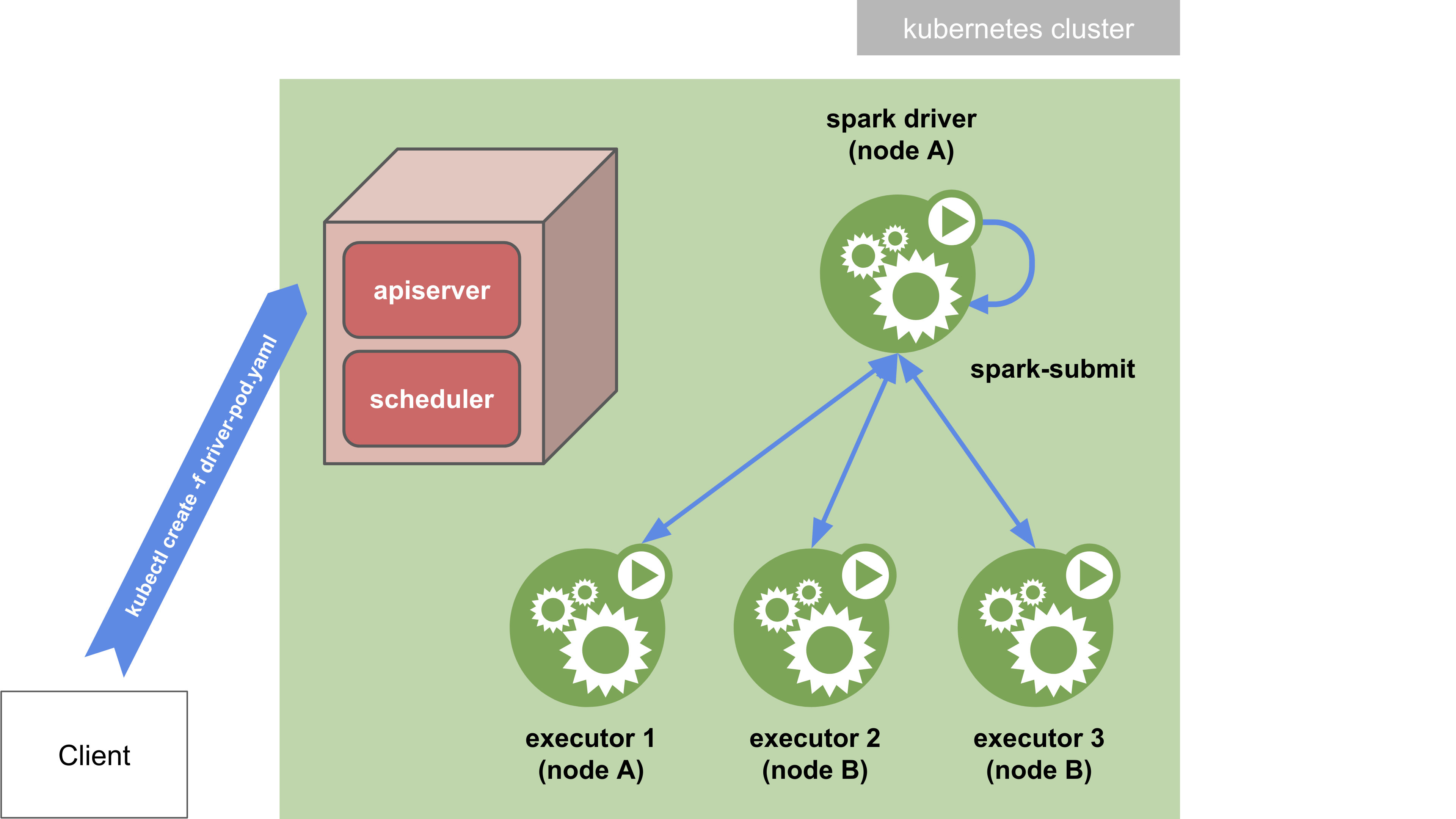
Spark-submit in client mode
In client mode, the spark-submit command is directly passed with its arguments to the Spark container in the driver
pod. With the deploy-mode option set to client, the driver is launched directly within the spark-submit process
which acts as a client to the cluster. The input and output of the application are attached to the logs from the pod.
Who Does What?
With “native” Spark, we will execute Spark applications in client mode, so as not to depend on a local Spark
distribution. Specifically, the user creates a driver pod resource with kubectl, and the driver pod will
then run spark-submit in client mode internally to run the driver program.
With Spark Operator, a SparkApplication should set .spec.deployMode to cluster, as client is not currently
implemented. Behind the scenes, the behavior is exactly the same as with native Spark: the operator’s controller
thus embeds a Spark distribution which plays the role of Spark scheduler; driver pods are spawned from the
controller… and then run spark-submit in client mode internally to run the driver program. But this is globally
transparent for the end user.
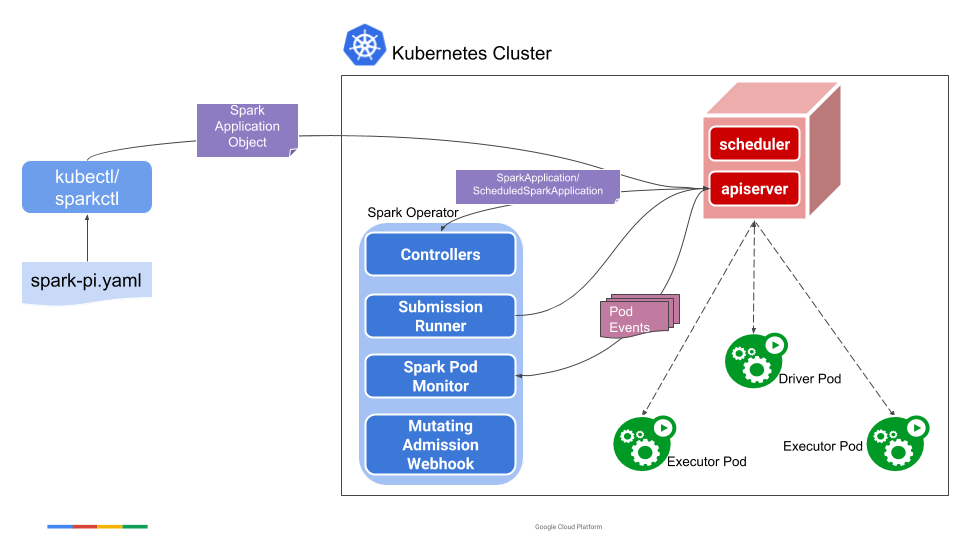
Additional details of how SparkApplications are run can be found in the
design documentation.
Driver Pod
With native Spark, the main resource is the driver pod. To run the Pi example program like with the Spark Operator, the driver pod must be created using the data in the following YAML file:
pyspark-pi-driver-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app-name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver
namespace: ${NAMESPACE}
spec:
containers:
- name: pyspark-pi
image: eu.gcr.io/yippee-spark-k8s/spark-py:3.0.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5678
name: headless-svc
- containerPort: 4040
name: web-ui
resources:
requests:
memory: 512Mi
cpu: 1
limits:
cpu: 1200m
env:
# Overriding configuration directory
- name: SPARK_CONF_DIR
value: /spark-conf
- name: SPARK_HOME
value: /opt/spark
# Configure all key-value pairs in ConfigMap as container environment variables
envFrom:
- configMapRef:
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
args:
- $(SPARK_HOME)/bin/spark-submit
- /opt/spark/examples/src/main/python/pi.py
- "10"
volumeMounts:
- name: spark-config
mountPath: /spark-conf
readOnly: true
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: In
values: [${DRIVER_NODE_AFFINITIES}]
priorityClassName: ${PRIORITY_CLASS_NAME}
restartPolicy: OnFailure
schedulerName: volcano
serviceAccountName: ${SERVICE_ACCOUNT_NAME}
volumes:
# Add the executor pod template in read-only volume, for the driver to read
- name: spark-config
configMap:
name: pyspark-pi-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
items:
- key: spark-defaults.conf
path: spark-defaults.conf
- key: spark-env.sh
path: spark-env.sh
- key: executor-pod-template.yaml
path: executor-pod-template.yaml
Don’t pay attention to the variable placeholders for now, even though you can imagine what they can be used for.
As you can see, the driver pod depends on other Kubernetes resources. We will detail each of them.
Spark Configuration
We use a ConfigMap for setting Spark configuration data separately from the driver pod definition.
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-cm
namespace: ${NAMESPACE}
data:
# Comma-separated list of .zip, .egg, or .py files dependencies for Python apps.
# spark.submit.pyFiles can be used instead in spark-defaults.conf below.
# PYTHONPATH: ...
spark-env.sh: |
#!/usr/bin/env bash
export DUMMY=dummy
echo "Here we are, ${DUMMY}!"
spark-defaults.conf: |
spark.master k8s://https://kubernetes.default
spark.submit.deployMode client
spark.executor.instances 2
spark.executor.cores 1
spark.executor.memory 512m
spark.kubernetes.executor.container.image eu.gcr.io/yippee-spark-k8s/spark-py:3.0.1
spark.kubernetes.container.image.pullPolicy IfNotPresent
spark.kubernetes.namespace spark-jobs
# Must match the mount path of the ConfigMap volume in driver pod
spark.kubernetes.executor.podTemplateFile /spark-conf/executor-pod-template.yaml
spark.kubernetes.pyspark.pythonVersion 2
spark.kubernetes.driver.pod.name spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver
spark.driver.host spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver-svc
spark.driver.port 5678
# Config params for use with an ingress to expose the Web UI
spark.ui.proxyBase /spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
# spark.ui.proxyRedirectUri http://<load balancer static IP address>
executor-pod-template.yaml: |
apiVersion: v1
kind: Pod
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: executor
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: In
values: [${EXECUTOR_NODE_AFFINITIES}]
priorityClassName: ${PRIORITY_CLASS_NAME}
schedulerName: volcano
Executor Pod Template
We use a template file in the ConfigMap to define the executor pod configuration.
Templates are typically used for
configuring Spark pods that cannot be configured otherwise, via Spark properties or environment variables
. Thus, template files mostly contain fine-grained configuration related to deployment at the Kubernetes level:
here, the node affinity and the priority class name.
To make the pod template file accessible to the spark-submit process, we must set the Spark property
spark.kubernetes.executor.podTemplateFile with its local pathname in the driver pod. To do so, the file will be
automatically mounted onto a volume in the driver pod when it’s created.
Executor Pod Garbage Collection
We must also set spark.kubernetes.driver.pod.name for the executors to the name of the driver pod. When this
property is set, the Spark scheduler will deploy the executor pods with an ownerReference, which in turn will
ensure that once the driver pod is deleted from the cluster, all of the application’s executor pods will also be
deleted.
Client Mode Networking
In client mode, the driver runs inside a pod. Spark executors must be able to connect to the Spark driver by the
means of Kubernetes networking. To do that, we use
a headless service to allow
the driver pod to be routable from the executors by a stable hostname. When deploying the headless service, we
ensure that the service will only match the driver pod and no other pods by assigning the driver pod a
(sufficiently) unique label and by using that label in the label selector of the headless service. We can then
pass to the executors the driver’s hostname via spark.driver.host with the service name and the spark driver’s
port to spark.driver.port.
spark-driver-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-driver-svc
namespace: spark-jobs
spec:
clusterIP: None
ports:
- name: 5678-5678
port: 5678
protocol: TCP
targetPort: 5678
selector:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
type: ClusterIP
Spark UI
Ingress
The Spark UI is accessible by creating a service of type ClusterIP which exposes the UI from the driver pod:
spark-ui-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-svc
namespace: spark-jobs
spec:
ports:
- name: spark-driver-ui-port
port: 4040
protocol: TCP
targetPort: 4040
selector:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
spark-role: driver
type: ClusterIP
With this service alone, the UI is only accessible from inside the cluster. We must then create an Ingress to expose
the UI outside the cluster. In order for the Ingress resource to work, the cluster must have an ingress controller
running. You can choose the
ingress controller implementation
that best fits your cluster.
Traefik and
Nginx are very popular choices. The ingress below is configured for
Nginx:
spark-ui-ingress.yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
labels:
app-name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}
name: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-ingress
namespace: spark-jobs
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/proxy-redirect-from: "http://$host/"
nginx.ingress.kubernetes.io/proxy-redirect-to: "http://$host/spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}/"
spec:
rules:
- http:
paths:
- path: /spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}(/|$)(.*)
backend:
serviceName: spark-${PRIORITY_CLASS_NAME}${NAME_SUFFIX}-ui-svc
servicePort: 4040
The Ingress is backed by as many services as driver pods that run concurrently in the cluster. Each UI must then be
addressed with a unique path in the Ingress. The path in question is directly derived from the name of the Spark
application, with its unique ID.
The interface is always available at http://<driver-pod-ip>:4040 (from inside the cluster), as each driver pod is
assigned a unique IP and there is only one SparkContext running in the pod host (otherwise, the UI would be bound
to successive ports beginning with 4040: 4041, 4042, etc).
So, natively, the different UIs that might be available at a given time on a same host are only differentiated by their
assigned port number. The UI has been designed following that principle, and all HTTP operations are performed
relatively to the same root path in the URL, which is…/.
So for the UI to be effectively accessible through the Ingress, we must set up HTTP redirection with an alternative
root path (the one configured in the Ingress). To work smoothly, the UI itself must be aware of this redirection by
setting spark.ui.proxyBase to this root path…and that’s it!
Spark Operator
The operator supports creating an optional Ingress for the Spark Web UI. This can be turned on by setting the
ingress-url-format command-line flag. The ingress-url-format should be a template like
{{$appName}}.{ingress_suffix}/{{$appNamespace}}/{{$appName}}. The {ingress_suffix} should be replaced by the user
to indicate the cluster’s Ingress url and the operator will replace the {{$appName}} and {{$appNamespace}} with
the appropriate value. Please note that Ingress support requires that cluster’s Ingress url routing is correctly
setup. For e.g. if the ingress-url-format is {{$appName}}.ingress.cluster.com, it requires that anything
*.ingress.cluster.com should be routed to the Ingress controller on the K8s cluster.
Example of Spark Operator install with the ingress-url-format command-line flag:
./helm install spark-operator incubator/sparkoperator --namespace spark-operator --set enableWebhook=true --set enableBatchScheduler=true --set ingressUrlFormat="\{\{\$appName\}\}.ingress.cluster.com"
Note that curly braces must be escaped.
Future Work
I could not enable the Spark Operator Ingress during my experiments, simply because a DNS name is required. Instead,
the same Ingress as for native Spark is “grafted” to the SparkApplication, with path-based routing.
The operation proposed by the Spark Operator, with routing based on hostname wildcards (for example
*.ingress.cluster.com), is nevertheless interesting as it would overcome the problem of HTTP redirect described
above.
With hostname wildcards, and therefore without the HTTP redirect, the UI service could be switched to NodePort
type (a NodePort service exposes the Service on each Node’s IP at a static port) and still be compatible with the
Ingress.
The UI would thus be accessible outside the cluster through both the Ingress with its external URL configured, and the
NodePort service at http://<node-ip>:<service-port>. A service of type NodePort is still relevant in a private
cloud.
Object Names and Labels
We use the app-name label to semantically group all the Kubernetes resources related to a single Spark application.
In our case, this label provides uniqueness, and we do not expect multiple Spark applications to carry the same value
for this label (at least in the namespace-time considered).
For a given Spark application, all the object names are then derived from the app-name. We simply add a suffix which
also qualifies the type of the object: -driver for the driver pod, -driver-svc for the driver service, -ui-svc
for the Spark UI service, -ui-ingress for the Spark UI ingress, and -cm for the ConfigMap.
We also set the label spark-role at the pod level to differentiate the drivers from their executors.
This naming and labeling is consistent with the Spark Operator. As a result, Spark applications can be treated and filtered in the same way, whether they are launched with the Spark Operator or with spark-submit. 👍
Deployment
We have now managed to mimic the same behavior we got with the Spark Operator, here is what we have deployed in Kubernetes:
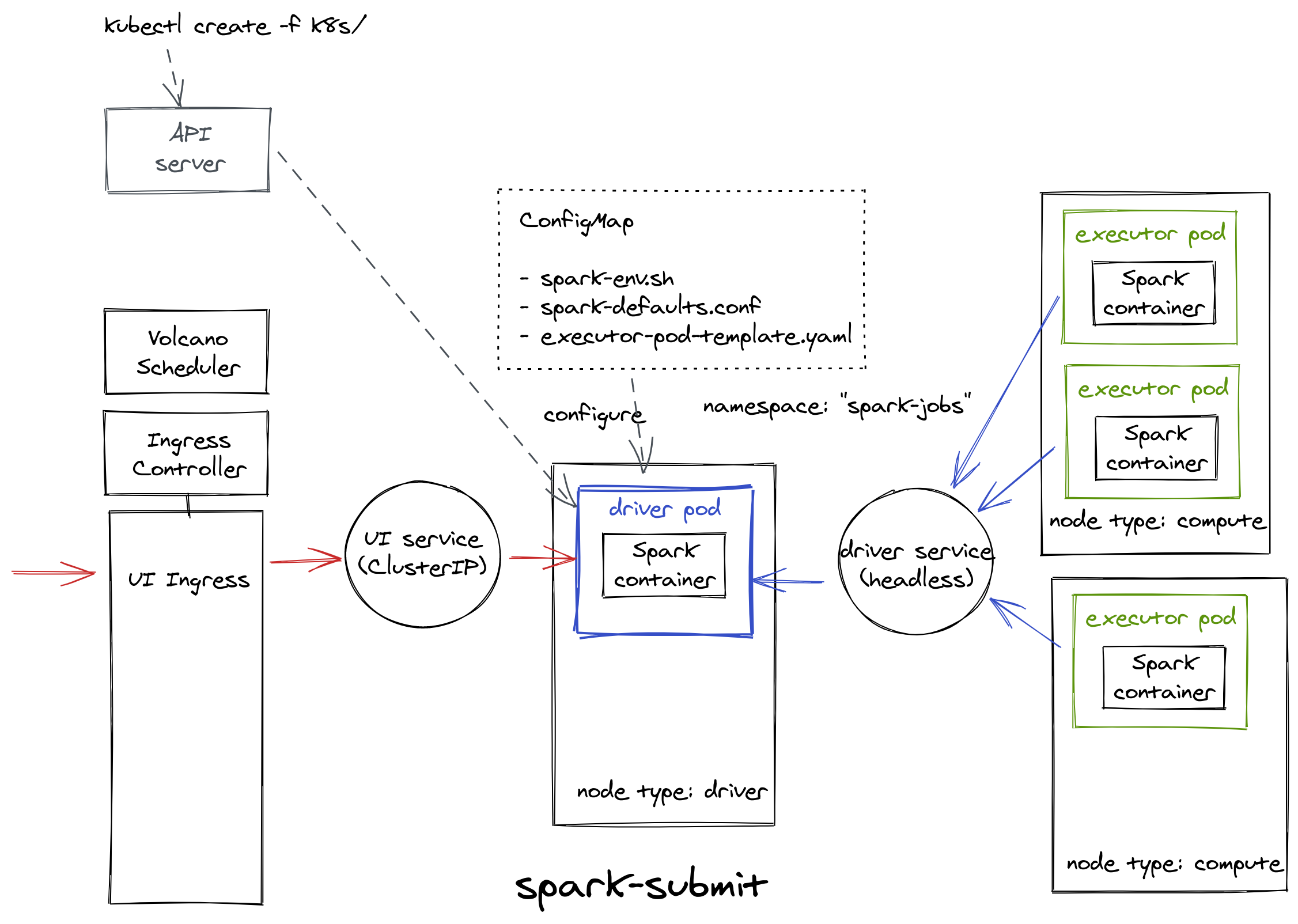
Now that we’ve defined all of our Kubernetes resources for spark-submit, we’re going to get our hands on some Python code to orchestrate all of this. See you in the third and final article in this series.